
Kao posledica bavljenja svojim diplomskim radom, došao sam do dela gde su mi bili potrebni nasumični brojevi (tema je određena primena genetskih algoritama, više o tome drugi put), pa sam odlučio malo ozbiljnije da ispitam razne mogućnosti za njihovo generisanje. Ispostavilo se da je u pitanju jedna veoma zanimljiva tema, čak i daleko opširnija nego što bi neko rekao na prvi pogled. Naravno, ono što je čini toliko zanimljivom jeste upravo njen naziv koji lako ume da nas zavara — nisu u pitanju nasumični brojevi, već “nasumični” (pseudonasumični) brojevi. O čemu se ovde zapravo radi?
Stvar je veoma jednostavna: nasumičnost ne postoji, a posebno ne u računarima. Čoveka možete priupitati da vam kaže proizvoljan broj, ali verovatnoća da taj čovek (ili žena) kao iz topa kaže devetmilionadvestapedesetišesthiljadatridesetisedam je daleko manja od verovatnoće da vam jednostavno kaže “osam”. Ukoliko se pogleda iz tog ugla, računari su zapravo mnogo bolji generatori nasumičnih brojeva, ali i dalje nisu savršeni.
Problem leži u tome što je u računarima sve determinističko, pa algoritam do nasumičnog broja mora da dođe na određen način koji je sve samo ne nasumičan. Jedan od jednostavnijih metoda je generisanje sekvence brojeva na sledeći način:
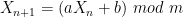
Očigledno, svaki od brojeva će biti iz intervala [0, m), gde će nasumičnost sekvence zavisiti od početne vrednosti koja se naziva seed (iliti seme), a neka vrednost će se u najboljem slučaju ponoviti nakon m generisanja (na osnovu trpanja golubova u rupe). Da bismo ovaj proces učinili “kvalitetnijim”, za seed se često koristi trenutno vreme (odnosno UNIX timestamp), pa drugo pokretanje programa nakon samo jedne sekunde može dati potpuno drugačije vrednosti. Mana ovog konkretnog pristupa je što se nakon prvog ponavljanja neke vrednosti cela sekvenca ponavlja; neki drugi pristupi nakon prvog ponavljanja vrednosti ipak daju drugačiju sekvencu, odnosno imaju mnogo veću periodu, jer i drugi parametri utiču na generisanje vrednosti. Složićete se, ipak, da ovakvo generisanje zapravo nije uopšte nasumično, ali je za potrebne mnogih i više nego dovoljno, dok za potrebe ostalih C++ nudi random_device generator koji se oslanja na adekvatan hardver, ukoliko je isti dostupan. Međutim, čak i ako imate dobar generator, to vas neće sprečiti da ga upropastite ukoliko ga uzmete zdravo za gotovo. Demonstrirajmo to na tri jednostavna primera.
Skraćivanje intervala
Recimo da želite da generišete brojeve od 0 do 3, a imate generator koji vam daje cele brojeve od 0 do 8. Logičan korak bi bio da jednostavno uzmete ostatak pri deljenju sa 4, što će vam dati željene vrednosti. Međutim, pogledajmo sledeću tabelu:
Nasumičan broj | 0 1 2 3 4 5 6 7 8 9 Dobijena vrednost | 0 1 2 3 0 1 2 3 0 1
Generisani brojevi su uniformno raspodeljeni, ali nakon uzimanja ostatka pri deljenju sa 4 ova raspodela više nije uniformna, jer 0 i 1 imaju veću verovatnoću da se pojave (3/10 naspram 2/10 za 2 i 3). Ovo će uvek biti slučaj kada dužina intervala generatora nije umnožak dužine traženog intervala. Rešenje za ovaj problem je da se pri dobijanju brojeva 8 i 9 izgeneriše nov broj, i tako sve dok ne dobijemo neki iz intervala [0, 7]. Srećom, generatori u svim jezicima rade sa jako velikim vrednostima, pa će za male intervale ove razlike u verovatnoćama biti zanemarljive, ali ih svejedno treba imati na umu.
Ovu situaciju sam imao pri računanju vrednosti broja π, gde je problem pravila parnost dužine intervala iz kojeg su vrednosti u jeziku C++. Ukoliko već niste, pročitajte taj kratak “eksperiment”, kako zbog skraćivanja intervala, tako i zbog demonstracije moći nasumičnih brojeva.
Širenje intervala
Ne toliko česta situacija, ali razmotrimo je rezonovanja radi. Neka generator daje brojeve iz intervala [0, 4], dok su nama potrebni brojevi [0, 8]. Generisanje dva broja i njihovo sabiranje jednostavno neće funkcionisati, jer:
+ | 0 1 2 3 4 ------------- 0 | 0 1 2 3 4 1 | 1 2 3 4 5 2 | 2 3 4 5 6 3 | 3 4 5 6 7 4 | 4 5 6 7 8
Brojevi 0 i 8 imaju najmanje šanse da budu generisani (1/25), dok 4 ima prilično dobru verovatnoću (1/5), što generator čini neuniformnim. Ali ako bismo napravili matricu na sledeći način:
| 0 1 2 3 4 ------------- 0 | 0 1 2 3 4 1 | 5 6 7 8 0 2 | 1 2 3 4 5 3 | 6 7 8 - - 4 | - - - - -
Ovo već funkcioniše. Svaka kombinacija dva nasumično generisana broja koju tretiramo kao uređeni par je podjednako verovatna, pa je samo potrebno da odbacimo neke kombinacije ne bi li i svaka krajnja vrednost bila podjednako verovatna (slična situacija kao kada posmatramo ostatak pri deljenju).
Generisanje realnih brojeva
Najzad, ukoliko su vam potrebni realni brojevi, a na raspolaganju imate samo generator celobrojnih vrednosti, moraćete da napišete funkciju koja vrši konverziju. Najjednostavniji način da to učinite jeste da generisanu vrednost množite sa određenim koeficijentom, tako da vam generisana nula daje donju granicu vašeg intervala, a generisana maksimalna vrednost gornju. Preciznije:
![[a,b]\ -\ interval\ iz\ kog\ vam\ je\ potreban\ broj](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D%5C+-%5C+interval%5C+iz%5C+kog%5C+vam%5C+je%5C+potreban%5C+broj&bg=ffffff&fg=000&s=0&c=20201002)
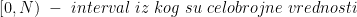
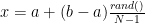
Ukoliko rand() vrati nulu, važiće x = a. Ukoliko rand() vrati N-1, važiće x = b. Ostale vrednosti za x će biti pravilno raspoređene između a i b.
Avaj, i ovde postoji jedan sitan problem. Ukoliko je N dovoljno veliko, a vaš interval dovoljno mali, granularnost će verovatno biti adekvatna. S druge strane, ukoliko je N malo, a raspon veliki, generisane vrednosti neće imati dovoljnu preciznost (biće redom, na primer, 0 0.12 0.24 0.36…). Naravno, u pitanju nije problem koji neće rešiti još nekoliko nasumičnih brojeva.
Ideja u ovom slučaju je da se željeni interval podeli na N manjih, jednakih intervala, od kojih će jedan biti odabran nasumičnom vrednošću od 0 do N-1. Kada je manji interval fiksiran, postupak se može ponavljati sve dok ne dođemo do intervala željene širine, odnosno do dovoljne preciznosti za naš problem.
Zaključak
Ukoliko vam je potrebno neko specifično generisanje nasumičnih brojeva, prvo ispitajte koje mogućnosti vam nudi programski jezik. C++, na primer, između ostalog nudi i uniformne distribucije celih i realnih brojeva nad proizvoljnim intervalima, a ne samo generisanje celih brojeva od 0 do RAND_MAX.
Međutim, ako imate samo jedan generator na raspolaganju, dobro razmislite kako ga možete adaptirati, a da pritom ne narušite uniformnost.
(Ili nemojte ni da se trudite. Brinite o tome kada se budete ozbiljno bavili kriptografijom.)
Ja bih samo dodao da obican rand() generise jako lose vrednosti koje po mom misljenju nisu dovoljno dobre ni za dice roll, a kamoli za nesto ozbiljnije.
Preporucujem odlican Mersenne Twister random generator kao zamenu — postoji C i C++ verzija, a ima ga i u PHP jeziku u vidu funkcije mt_rand(). Takodje, na novim Intel procesorima (od Ivy Bridge pa nadalje) postoji i hardverski generator u jezgru koji se koristi preko masinske instrukcije RDRAND ili intrinsic funkcija _rdrand16_step(), _rdrand32_step(), i _rdrand64_step() koje su podrzane od Visual Studio 2010 SP1.